



Log File e la Seo
Come sfruttare i file di Log per ottimizzare la SEO di un sito Web

Cosa sono i File di Log?
Nel 2025, la SEO non può più fare affidamento esclusivamente sui crawl: è tempo di immergersi nei file di log. I log web non sono solo tracce tecniche, ma rivelatori potenti del comportamento dei bot di ricerca reali—e non simulati (se non spoffed). Con Screaming Frog Log File Analyser, analizzare i file di log diventa accessibile a ogni SEO, permettendo di scoprire:
• quali URL stanno realmente venendo scansionati da Googlebot (e quali vengono ignorati),
• dove si disperde il crawl budget e quali errori 404 o redirect meritano priorità,
• pagine orfane, contenuti non indicizzati, e anomalie strutturali una volta invisibili.
Grazie a questo strumento, i professionisti SEO possono trasformare i log da semplice testo grezzo a insight strategici fondamentali per ottimizzare l’architettura del sito e garantire una scansione coerente e mirata. In un’epoca in cui la SEO è sempre più tecnica e orientata ai dati reali, il log file SEO non è più un’opzione ma una necessità.
I server web producono anche altri file di log, come i log degli errori, ma per le analisi prettamente SEO ci servono solamente i log di accesso a un sito web.
Perchè analizzare i File di Log?
I file di log sono un modo incredibilmente potente, ma ancora poco utilizzato, per ottenere preziose informazioni su come ogni Motore di Ricerca esegue la scansione del tuo sito.
È per questo motivo che ogni Seo dovrebbe analizzarli anche se i log di accesso potrebbero essere difficili da ottenere dal cliente (e/o dal provider di hosting, server e team di sviluppo).
L’analisi dei file di log può aiutarti ad ottenere i seguenti risultati:
- Verificare esattamente cosa può o non può essere scansionato. Un crawl è una simulazione, mentre i file di log mostrano esattamente ciò che è stato scansionato (full story).
- Visualizzare le risposte incontrate dai motori di ricerca durante la loro scansione (e comparare i dati nelle diverse scansioni nel tempo). Con l’analisi dei Log Files i problemi possono essere qualitativamente definiti. Se trovi diversi 404 sul tuo sito durante un crawl, è difficile capire quali sono i più importanti; analizzando i file di log, potrai vedere con quale frequenza si sono verificati, aiutandoti a prioritizzare la loro risoluzione.
- Identificare le carenze di scansione, che potrebbero avere implicazioni più ampie a livello di sito (come la gerarchia o la struttura dei link interni).
- Vedere quali pagine i motori di ricerca danno la priorità e considerano le più importanti e quali potrebbero essere ottimizzate per ottenere una frequenza di scansione più consona. Questa condizione è sottovalutata ma spesso accade che la visione strategica del sito web non corrisponde alle risposte del Motore di Ricerca.
- Scoprire aree di spreco del budget di scansione (Crawl Budget).
- Vedere gli URL orfani. Se un URL non è collegato internamente, non sarà trovato scansionando il sito. Gli URL collegati solo esternamente (o storicamente) saranno riportati nei log permettendo di gestirli, ottimizzarli o eliminarli.
- Visualizza i cambiamenti nel tempo. Un crawl è una fotografia del momento, mentre i file di log forniscono informazioni storiche su ogni risorsa.
Grazie all’analisi di questi preziosissimi dati sarai in grado di preservare il Crawling Budget e definire quali siano gli elementi che negativamente stanno impattando sulla navigazione del BOT.
Vediamo di seguito delle criticità molto comuni:
- Navigazione a faccette e identificatori di sessione.
- Contenuti duplicati sul sito.
- Pagine di errore soft.
- Pagine hackerate.
- Spazi infiniti e proxy.
- Contenuti di bassa qualità e spam.
Pertanto, è utile evitare di far sprecare tempo ed energia al BOT nella scansione di URL di questo tipo, poiché riduce l’attività e causa ritardi nella scansione delle pagine più importanti.
Log File Analyser
La base dell’analisi dei file di log è essere in grado di verificare esattamente quali URL sono stati scansionati dai bot dei motori di ricerca. Attraverso “Log File Analyser” potrai importare i tuoi file di log semplicemente trascinando e rilasciando il file di direttamente nell’interfaccia e verificare automaticamente i bot dei Motori di Ricerca.
Dopo l’importazione potrai utilizzare il filtro “Stato di Verifica” per visualizzare solo quelli verificati e il filtro “User-Agent” per ottenere “tutti i bot” o isolare un Bot in particolare come ad esempio “Googlebot” o “Googlebot per smartphone” per analisi granulari.
Dopo questo setup molto semplice ed intuitivo otterrai esattamente gli URL che sono stati scansionati dal Bot filtrati nella scheda “URL” classificandoli in base al numero degli eventi generati in un dato periodo di tempo.
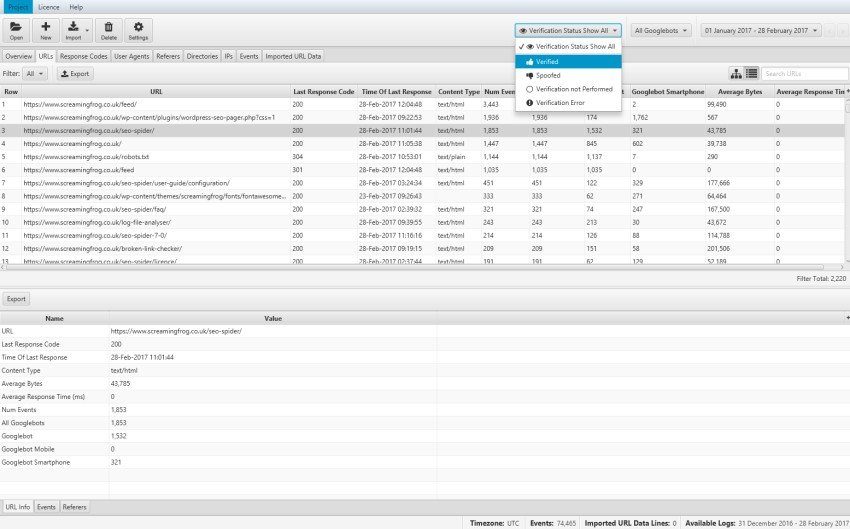
Identificare URL basso Valore
Il contenuto per la Seo è uno degli elementi di ranking più importanti e comprendere quali URL vengono crawlati e la loro frequenza ti potrà aiutare a scoprire potenziali aree di spreco del “Crawling Budget” che magari presentano “facetted navigation”, ID di sessione o contenuti duplicati.
Ad esempio attraverso la barra di ricerca del tool potresti cercare la presenza di un punto interrogativo (?) nel “Path URL” (frequentemente presente negli e-commerce con filtri), che ti aiuterà ad identificare URL con parametri magari non “canonicalizzati” e frequentemente navigati dal Bot di Google.

Come puoi vedere nell’esempio qui sopra la prima voce ha generato 57 eventi che corrispondono ai commenti di WordPress, quindi non esattamente una risorsa di alto valore. Nel caso specifico sarà sufficiente disabilitare i commenti per risolvere questo scenario e salvaguardare il Crawl Budget.
Cliccando sull’intestazione di colonna “URL” sarà possibile classificarli in ordine alfabetico e scoprire gli URL che differiscono solo per id sessione o parametri che non dovrebbero essere a disposizione della scansione del BOT.
Cliccando su “Num Events” avrai a disposizione le risorse che presentano, in un intervallo di tempo, una frequenza di scansione maggiore e minore.
Analisi Frequenza di Scansione
La frequenza con cui Googlebot richiede una pagina si basa su una serie di fattori come ad esempio la freschezza del contenuto o il “Ranking” attribuito da Google ad una risorsa in relazione alle altre. Nonostante questo concetto sia banalizzato, è molto utile analizzare il numero di eventi per URL come indicatore per aiutarti ad identificare eventuali problemi di fondo tra le risorse.
Attraverso i filtri nel menu della barra principale sarai in grado di scegliere anche quali eventi sono generati dal singolo Spider considerando anche Bot come Bing, Yandex o altri che potrebbero influire sui dati e creare dei “falsi positivi” nelle analisi strategiche o appesantire in modo drastico il carico del server.

Lasciando l’impostazione di default “All BOT” invece avrai una visione di insieme degli eventi elaborati per URL e una divisione degli Spider scorrendo verso destra nella Tab.

Frequenza di Scansione Sottodirectory
Il passaggio successivo nell’analisi dei file di log è quello di considerare le sotto directory (Tab Directory).
In questo modo sarà possibile comprendere eventuali aree performanti o aree da ottimizzare che magari presentano criticità che non permettono al crawler di navigare in modo lineare.
Con un focus delle sotto cartelle sarai in grado di scoprire eventuali “Waste Area”.
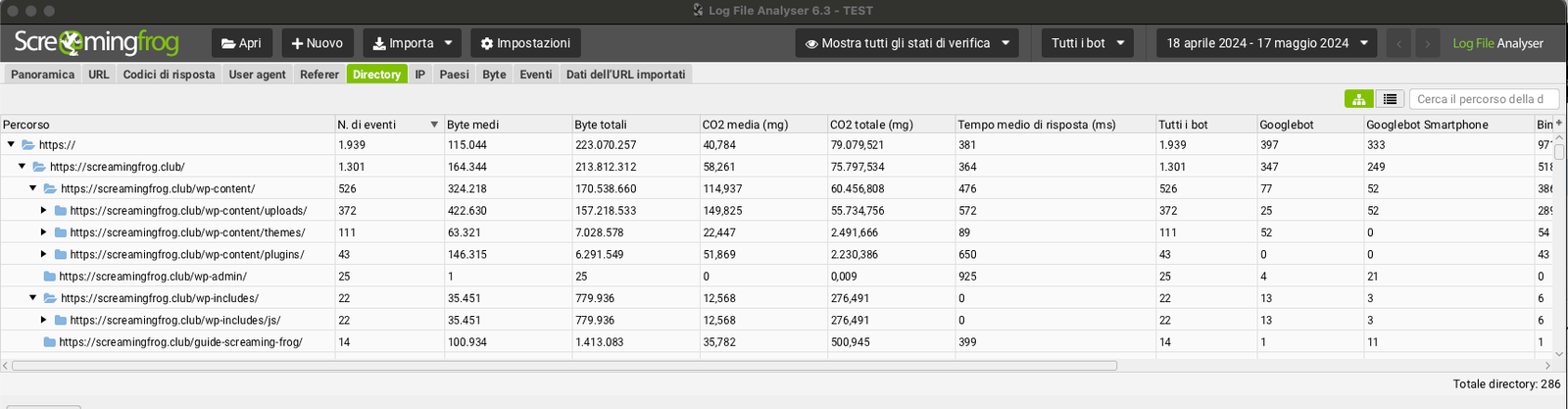
Frequenza di Scansione Contenuti
Mentre i file di log di per sé non contengono un tipo di contenuto, il Log File Analyser analizza gli URL per i formati più comuni e consente di filtrare facilmente la frequenza di crawl per tipo di contenuto, che si tratti di HTML, immagini, JavaScript, CSS, PDF ecc.
Attraverso questo scenario di analisi sarai in grado di interpretare quanto tempo Google dedica in proporzione al crawling di ciascun tipo di contenuto.

Frequenza di Scansione per User Agent
Un altro punto di analisi è quello legato alla frequenze di crawl in base ai diversi user-agent, che potranno aiutarti a capire le rispettive prestazioni di ogni singolo Motore di Ricerca.
In base a questo indice sarà possibile definire il numero di URL unici crawlerati nel periodo di tempo analizzato fornendo un’indicazione approssimativa del tempo che ciascun motore di ricerca potrebbe impiegare per scansionare tutti gli URL del sito. In questo modo avrai una panoramica del “Crawl Budget” (Crawl Rate) che viene dedicato al tuo progetto online.
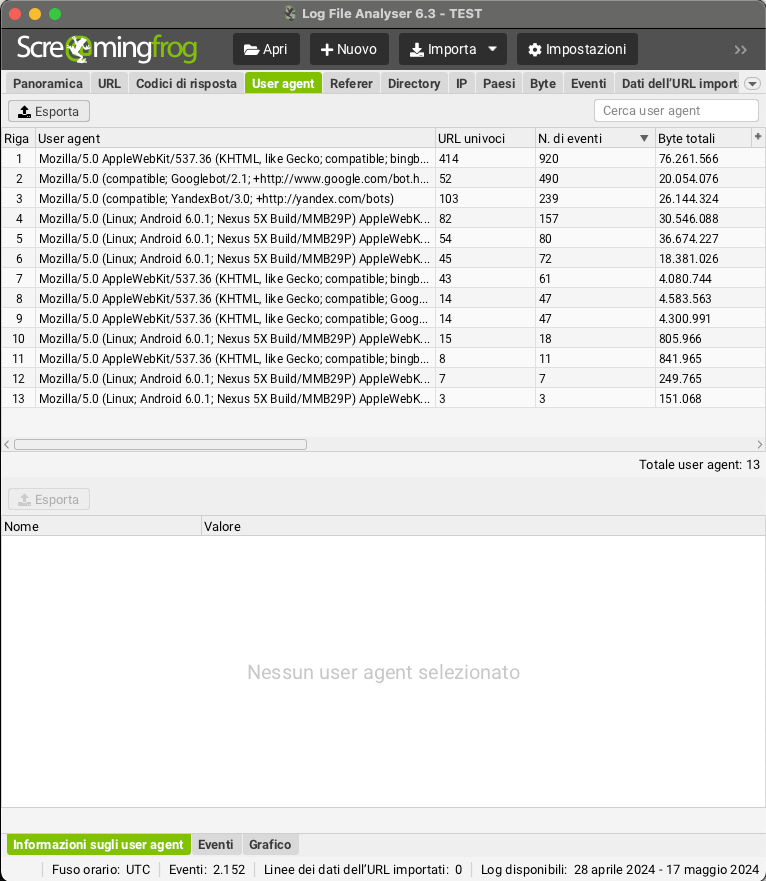
Molto interessante comprendere il comportamento dei vari Bot ma soprattutto vitale se il comportamento di “Googlebot” e “Googlebot per smartphone” è diversificato. Ad esempio potrai comprendere se ci siano dei coni di bottiglia nella versione mobile oppure capire se il sito viene considerato “mobile first indexing”.
URL Crawl al giorno, settimana e al mese
Attraverso la funzione “Panoramica” avrai un riepilogo puntuale degli eventi complessivi del periodo selezionato con una dashboard molto visuale e intuitiva.
Un altro punto di vista durante l’analisi dei file di log è quello di considerare il numero totale di URL unici che sono stati sottoposti a crawling, nonché il numero di URL unici sottoposti a crawling ogni giorno. In questo caso sarà quindi possibile stimare quanti giorni potrebbero essere necessari ai Motori di Ricerca per effettuare un re-crawling completo di tutti i vostri URL.

La dashboard permette di esportare in formato “.csv” i dati dei grafici e, passando sui nodi del grafico vedere granularmente i risultati dei log in base ai diversi user-agent o status code..
Analisi 404 e Server Errors
I Log consentono di analizzare rapidamente l’ultimo codice di risposta che i Motori di Ricerca hanno riscontrato per ogni URL che è stato sottoposto a crawling.
Nella scheda “codici di risposta”, è possibile utilizzare il filtro per visualizzare gli errori 4XX del client per scoprire i link non funzionanti, o gli errori 5XX del server.
È inoltre possibile vedere quali sono gli URL potenzialmente più importanti da correggere, poiché sono ordinati in base alla frequenza di crawling.
Analisi 404: Screaming Frog o File di Log?
Screaming Frog permette di analizzare tutti i collegamenti presenti ed eventuali errori 404 tra i collegamenti interni o verso risorse esterne ma si limita a quello.
Con i file di log si possono identificare anche URL non più presenti sul progetto in analisi ma che magari erano stati indicizzati nel database di Google in versioni precedenti del sito web (non coperti da migrazioni seo precedenti).
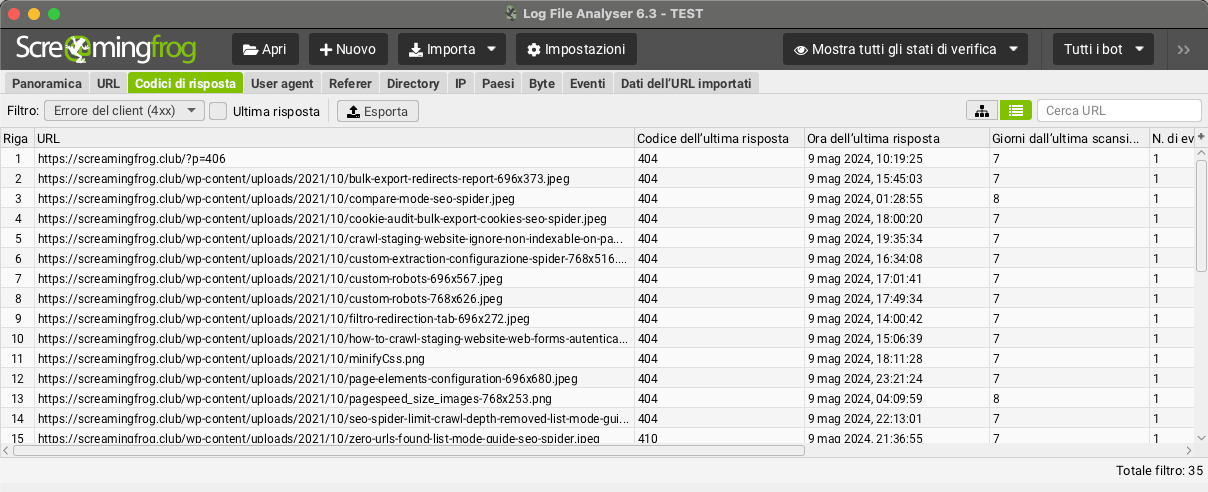
In questa fase di analisi è importante ricordate di spuntare la casella “ultima risposta” accanto al filtro 4xx, altrimenti il “Log File Analyser” presenterà tutti gli URL che hanno un evento corrispondente nel tempo (anziché solo l'”ultima risposta” /”Last Response“) dando a volte un risultato non conforme dato che l’errore potrebbe essere stato già risolto rispetto al primo giorno in cui si è iniziato a registrare i file di log.
Inconsistent Responses
Un filtro molto interessante, che riprende quanto detto nel punto precedente è “incosistent” (Incoerenti) che ti aiuta ad identificare quali risorse presentano delle risposte incoerenti tra i risultati; ad esempio perché un link non funzionante è stato successivamente corretto, oppure perché il sito presenta un maggior numero di errori interni al server in condizioni di carico e vi è un problema intermittente che deve essere indagato.

Audit Redirect
Attraverso le registrazioni dei log sarà possibile visualizzare tutti gli URL che i motori di ricerca richiedono e che ricevono come risposta un re-indirizzamento.
Questo aspetto non comprende solamente i redirect presenti sul sito, ma anche quelli storici, che vengono ancora richiesti di tanto in tanto, magari dovuti a migrazioni precedenti.
Per visualizzare gli Url con status code 3xx sarà sufficiente utilizzare la tab relativa con il filtro “Reindirizzamento (3XX)”, insieme alla casella “Ultima risposta”.
Bot Spoofed
La scheda IP e il filtro “stato di verifica” impostato su “spoofed” consentono di visualizzare rapidamente gli indirizzi IP delle richieste che emulano i bot dei motori di ricerca, utilizzando la loro stringa di user-agent, ma senza verificarli. Attraverso questi dati sarà possibile bloccare le scansioni e, di conseguenza alleggerire il lavoro del server.

Se si modifica il filtro “stato di verifica” in “verificato”, è possibile visualizzare tutti gli IP dei bot dei motori di ricerca verificati. Questo può essere utile quando si analizzano siti web che hanno pagine adatte alla localizzazione e che servono contenuti diversi in base al Paese.
Identificare Pagine grandi dimensione
Un altro elemento molto importante durante le analisi dei file di log sono i diversi tempi di risposta delle singole risorse alle richieste dei Bot.
Pagine molto pesanti e poco performanti incidono notevolmente sul budget di crawling , cosicché analizzando i “byte medi” degli URL, sarà facile e veloce identificare le aree che dovranno essere ottimizzate.
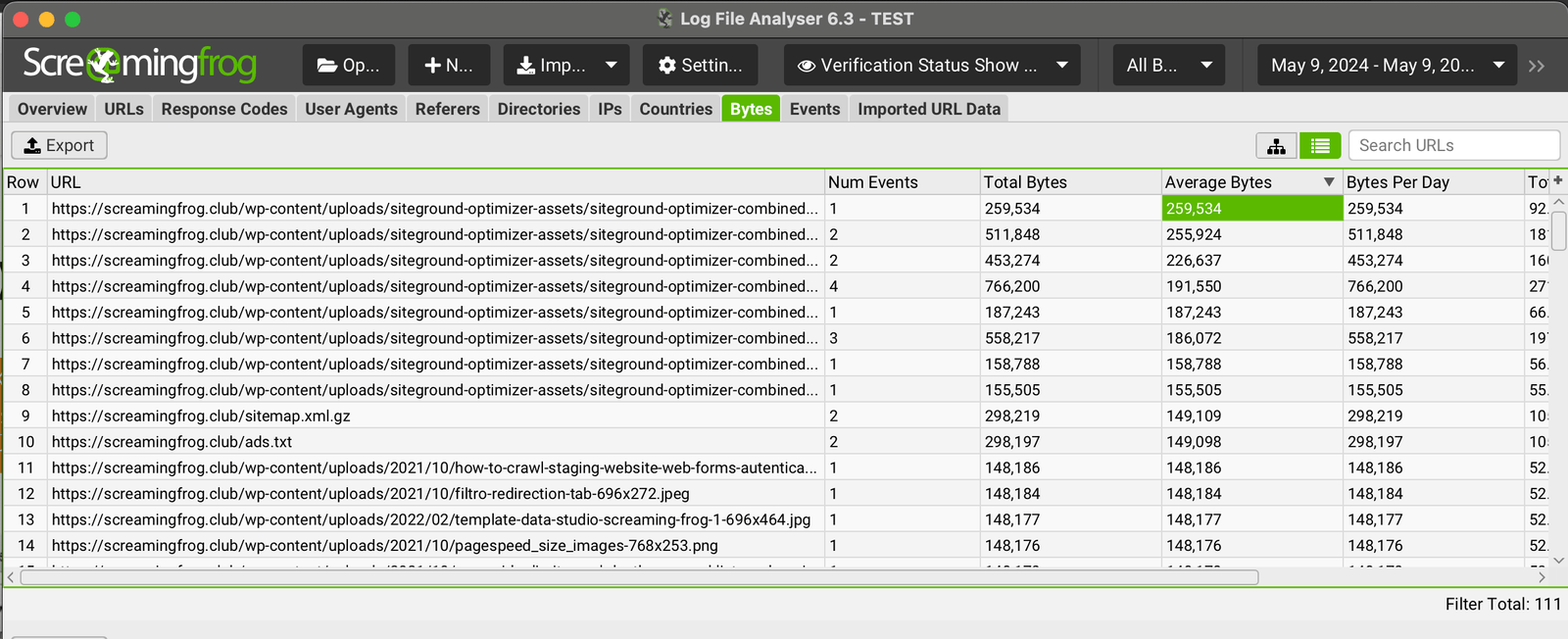
Analisi Crawl vs Log File
Una delle analisi più interessanti dei log file è la comparazione degli stessi con i dati ottenuti tramite un crawl. Attraverso questa comparazione sarai in grado di comprendere se alcuni URL o intere aree del tuo sito non ottengono scansioni da parte dello Spider.
Sarà sufficiente scaricare gli URL ottenuti con una scansione di Screaming Frog in formato “.csv” ed importarli in Log File Analyser, attraverso il filtro “Not in Log File” della tab URL potrai trovare con semplicità le aree su cui intervenire per migliorare la navigabilità da parte del BOT, come ad esempio il Linking Interno.
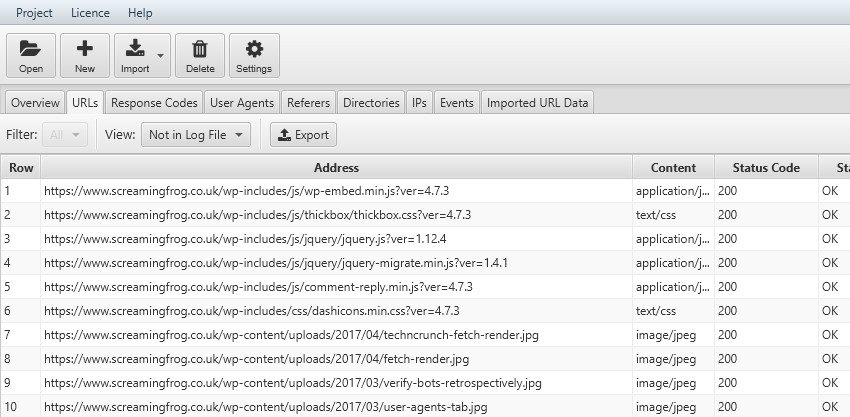
Rovesciando l’analisi “Not in URL DATA” ci saranno gli URL presenti nelle navigazioni dei Bot ma non nella scansione con Screaming Frog; in questo scenario potrai trovare tutti gli eventi generati da indirizzi non più presenti o pagine Orfane che non sono collegate, ma presenti nel sito in analisi. Quest’ultimo punto è analizzabile anche con le API di Ga4 e Search Console che permettono di trovare risorse che ricevono Impression o visite senza essere collegate internamente (es. pagine con link da siti esterni).
Hacking e Log File
I File di Log diventano essenziali in caso di hacking o malware sul sito. Molte volte ci si accorge che un progetto online è stato compromesso troppo tardi magari tramite avvisi da parte della search console o per un drastico calo in Serp dovuto a penalizzazioni manuali.
In questo caso, la scansione e la rimozione degli URL (“410”- gone) compromessi potrebbe non essere sufficiente (soluzione istantanea) e i file di Log ti permetteranno di constatare quali siano i reali danni dell’attacco informatico per il Motore di Ricerca e avere una visione completa delle pagine o cartelle create che continuerebbero a fare dei danni se non cancellate completamente.
Un caso molto frequente potrebbe essere un file di codice “.php” o altro che in modo intermittente genera nuove risorse spammose; in questo caso la sola scansione risulterebbe insufficiente mentre attraverso i file di log avresti diversi alert nel tempo con relativo tempo per la sistemazione.
Top Crawled Pages
Dopo questo approfondimento avrai sicuramente compreso l’importanza dei File di Log ma vorrei porre la tua attenzione anche su un altro aspetto differente dalla mera ricerca degli errori.
La conoscenza dei Log ti permette una visione a 360° sulla strategie e architettura del sito web. Infatti potresti confrontare le Top Pages per i motori di ricerca (in base agli eventi) e quali dovrebbero essere le tue pagine più visitate. Se ci fossero delle incongruenze sarai immediatamente in grado di fare delle modifiche dell’Internal Linking o ristrutturare la tua architettura o il “Crawl Depth” dele singole risorse per poi inviare una nuova sitemap aspettando la risposta del Bot.

RAFFAELE VISINTIN
Consulente Seo e autore delle guide di Screaming Frog Club.
