




Que sont les Log File ?
Les serveurs web produisent également d’autres fichiers journaux, tels que les journaux d’erreurs, mais pour les analyses purement SEO, nous n’avons besoin que des journaux d’accès à un site web.
Pourquoi analyser les fichiers journaux ?
Les fichiers journaux sont un moyen incroyablement puissant, mais encore sous-utilisé, d’obtenir des informations précieuses sur la manière dont chaque moteur de recherche explore votre site.
C’est pourquoi tout référenceur devrait les analyser, même s’il est difficile d’obtenir les logs d’accès auprès du client (et/ou de l’hébergeur, du serveur et de l’équipe de développement).
L’analyse des fichiers journaux peut vous aider à obtenir les résultats suivants :
- Vérifiez exactement ce qui peut et ne peut pas être scanné. Un crawl est une simulation, tandis que les fichiers journaux montrent exactement ce qui a été parcouru (histoire complète).
- Visualisez les réponses rencontrées par les moteurs de recherche au cours de leur exploration (et comparez les données de différentes explorations au fil du temps). L’analyse des fichiers journaux permet de définir qualitativement les problèmes. Si vous trouvez plusieurs 404 sur votre site lors d’une exploration, il est difficile de savoir lesquels sont les plus importants ; en analysant les fichiers journaux, vous pouvez voir combien de fois ils se sont produits, ce qui vous aide à donner la priorité à leur résolution.
- Identifier les lacunes de l’analyse, qui peuvent avoir des implications plus larges au niveau du site (telles que la hiérarchie ou la structure des liens internes).
- Voyez quelles sont les pages que les moteurs de recherche privilégient et considèrent comme les plus importantes et quelles sont celles qui pourraient être optimisées pour une fréquence d’exploration plus appropriée. Cette condition est sous-estimée, mais il arrive souvent que la vision stratégique du site web ne corresponde pas aux réponses du moteur de recherche.
- Découvrir les zones de gaspillage dans le budget rampant.
- Voir URL orphelins. Si une URL n’est pas liée en interne, elle ne sera pas trouvée lors de l’analyse du site. Les URL externes (ou historiques) seront signalés dans les journaux, ce qui permettra de les gérer, de les optimiser ou de les supprimer.
- La vue change au fil du temps. Un crawl est un instantané du moment, tandis que les fichiers journaux fournissent des informations historiques sur chaque ressource.
En analysant ces données précieuses, vous serez en mesure de préserver le budget d’exploration et de définir les éléments qui ont un impact négatif sur la navigation du BOT.
Nous allons examiner ci-dessous quelques points critiques très courants :
- Navigation à facettes et identifiants de session.
- Contenu dupliqué sur le site.
- Pages d’erreur molles.
- Pages piratées.
- Espaces infinis et substituts.
- Contenu de faible qualité et spam.
Il est donc utile d’éviter de gaspiller le temps et l’énergie du BOT en analysant des URL de ce type, car cela réduit l’activité et entraîne des retards dans l’analyse des pages les plus importantes.
Analyseur de Log File
La base de l’analyse des fichiers journaux est de pouvoir vérifier exactement quels URL ont été scannés par les robots des moteurs de recherche. Grâce à l‘ »analyseur de fichiers journaux », vous pouvez importer vos fichiers journaux par simple glisser-déposer directement dans l’interface et vérifier automatiquement les robots des moteurs de recherche.
Après l’importation, vous pouvez utiliser le filtre « Verification Status » pour afficher uniquement les robots vérifiés et le filtre « User-Agent » pour obtenir « tous les robots » ou isoler un robot particulier tel que « Googlebot » ou « Googlebot for smartphones » pour une analyse granulaire.
Après cette configuration très simple et intuitive, vous obtiendrez exactement les URL qui ont été analysées par le bot filtrées dans l’onglet « URLs » en les classant selon le nombre d’événements générés au cours d’une période donnée.
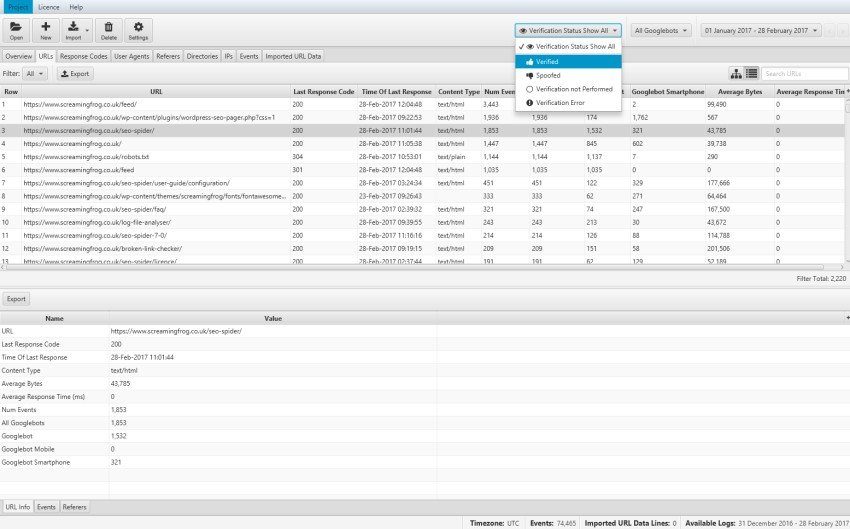
Identifier les URL de faible valeur
Le contenu pour le référencement est l’un des éléments de classement les plus importants, et le fait de savoir quelles URL sont explorées et à quelle fréquence peut vous aider à découvrir des zones potentielles de budget d’exploration gaspillé qui peuvent avoir une « navigation à facettes », des ID de session ou du contenu dupliqué.
Par exemple, en utilisant la barre de recherche de l’outil, vous pouvez rechercher la présence d’un point d’interrogation ( ?) dans le « Path URL » (fréquemment trouvé dans le commerce électronique avec des filtres), ce qui vous aidera à identifier les URL avec des paramètres peut-être non « canonisés » fréquemment parcourus par le robot Google.

Comme vous pouvez le voir dans l’exemple ci-dessus, la première entrée a généré 57 événements correspondant à des commentaires WordPress, ce qui n’est pas exactement une ressource de grande valeur. Dans ce cas, il suffira de désactiver les commentaires pour résoudre ce scénario et sauvegarder le Crawl Budget.
En cliquant sur l’en-tête de la colonne « URLs », il sera possible de les trier par ordre alphabétique et de découvrir les URLs qui ne diffèrent que par l’identifiant de session ou les paramètres qui ne devraient pas être disponibles pour l’analyse de BOT.
En cliquant sur « Nombre d’événements », vous obtiendrez les ressources dont la fréquence de balayage est la plus élevée et la plus basse dans un intervalle de temps donné.
Analyse de la fréquence de balayage
La fréquence à laquelle Googlebot demande une page dépend d’un certain nombre de facteurs tels que la fraîcheur du contenu ou le « classement » attribué par Google à une ressource par rapport à d’autres. Bien que ce concept soit banalisé, il est très utile d’analyser le nombre d’événements par URL en tant qu’indicateur pour vous aider à identifier les problèmes sous-jacents entre les ressources.
Grâce aux filtres du menu de la barre principale, vous pourrez également choisir les événements générés par le spider individuel, en tenant compte des bots tels que Bing, Yandex ou autres qui pourraient affecter les données et créer des « faux positifs » dans les analyses stratégiques ou alourdir considérablement la charge du serveur.

En laissant le paramètre par défaut « Tous les BOT », vous obtenez une vue d’ensemble des événements traités par URL et une division des spiders en faisant défiler l’onglet vers la droite.

Sous-répertoire des fréquences de balayage
L’étape suivante de l’analyse des fichiers journaux consiste à examiner les sous-répertoires (onglet Répertoire).
De cette manière, il sera possible de comprendre les éventuels domaines de performance ou les domaines à optimiser qui présentent peut-être des criticités ne permettant pas au crawler de naviguer de manière linéaire.
En vous concentrant sur les sous-dossiers, vous serez en mesure de découvrir toute « zone de gaspillage ».
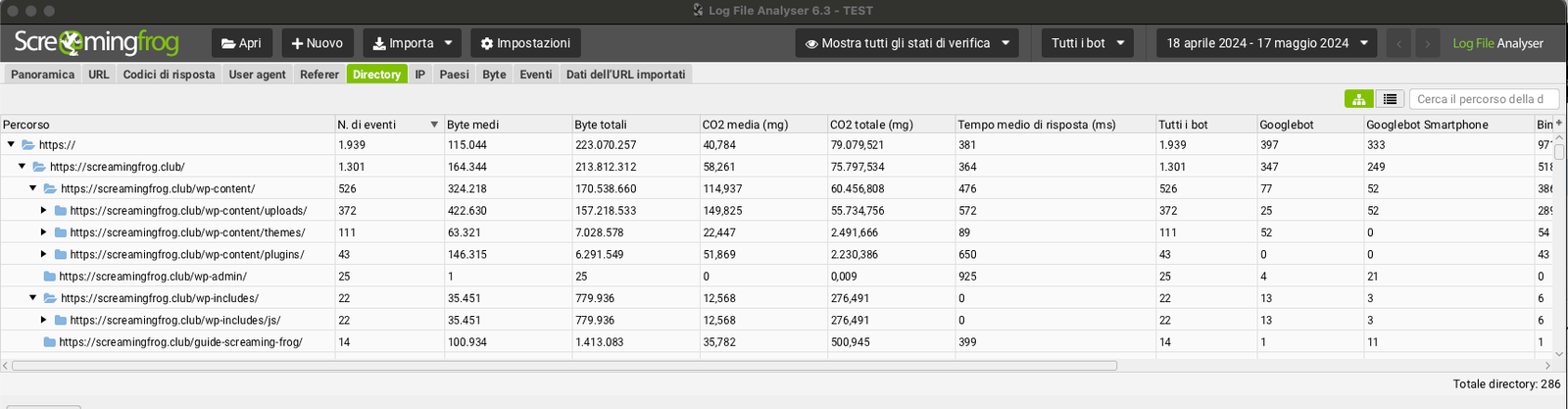
Fréquence de balayage Contenu
Bien que les fichiers journaux ne contiennent pas de type de contenu en soi, l’analyseur de fichiers journaux analyse les URL pour les formats les plus courants et permet de filtrer facilement la fréquence d’exploration par type de contenu, qu’il s’agisse de HTML, d’images, de JavaScript, de CSS, de PDF, etc.
Grâce à ce scénario d’analyse, vous serez en mesure d’interpréter le temps que Google consacre proportionnellement à l’exploration de chaque type de contenu.

Fréquence de balayage par agent utilisateur
Un autre point d’analyse concerne les fréquences d’exploration en fonction des différents agents utilisateurs, ce qui peut vous aider à comprendre les performances respectives de chaque moteur de recherche.
Sur la base de cet index, il sera possible de définir le nombre d’URL uniques parcourus au cours de la période analysée, ce qui donnera une indication approximative du temps nécessaire à chaque moteur de recherche pour parcourir toutes les URL du site. Vous aurez ainsi un aperçu du « budget de crawl » (taux de crawl) consacré à votre projet en ligne.
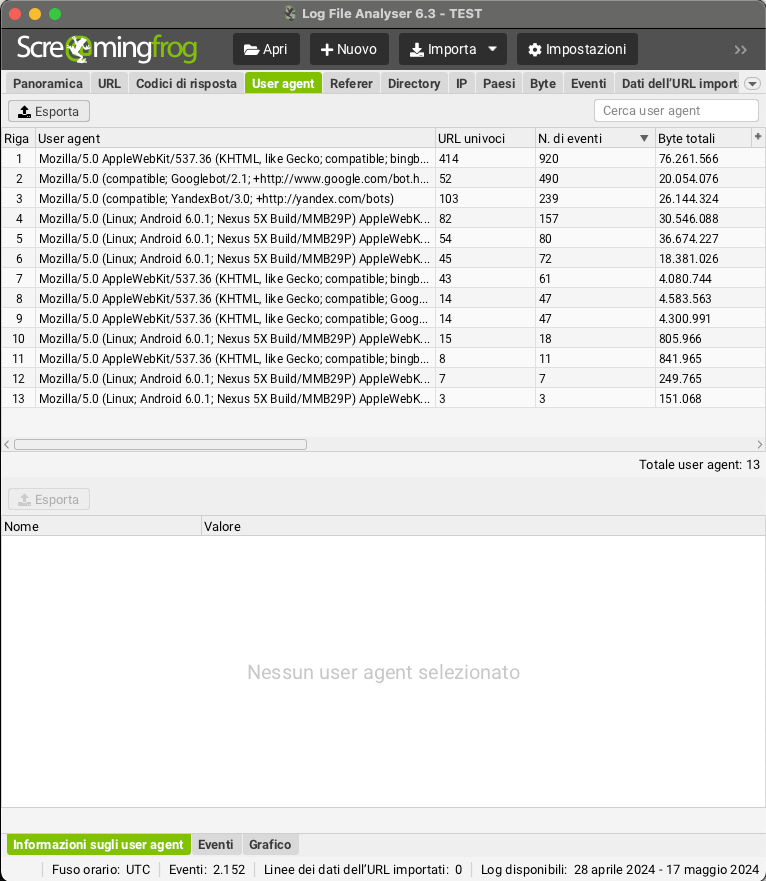
Il est très intéressant de comprendre le comportement des différents bots, mais c’est particulièrement important si le comportement des « Googlebots » et des « Googlebots pour smartphones » est différent. Par exemple, vous serez en mesure de comprendre s’il existe des goulets d’étranglement dans la version mobile ou si le site est considéré comme « mobile first indexing ».
URL Crawl par jour, semaine et mois
Grâce à la fonction « Vue d’ensemble », vous obtiendrez un résumé opportun des événements globaux de la période sélectionnée à l’aide d’un tableau de bord très visuel et intuitif.
Un autre point de vue lors de l’analyse des fichiers journaux est de considérer le nombre total d’URL uniques qui ont été parcourus, ainsi que le nombre d’URL uniques parcourus chaque jour. Dans ce cas, il sera possible d’estimer le nombre de jours nécessaires pour que les moteurs de recherche recensent l’ensemble de vos URL.

Le tableau de bord permet d’exporter les données du graphique au format « .csv » et, en passant sur les nœuds du graphique, de voir de manière granulaire les résultats du journal en fonction des différents agents-utilisateurs ou des codes d’état.
Analyse 404 et erreurs de serveur
Les journaux permettent d’analyser rapidement le dernier code de réponse que les moteurs de recherche ont rencontré pour chaque URL qui a été explorée.
Dans l’onglet « codes de réponse », vous pouvez utiliser le filtre pour afficher les erreurs client 4XX afin de découvrir les liens brisés, ou les erreurs serveur 5XX.
Il est également possible de voir quelles URL sont potentiellement les plus importantes à corriger, car elles sont classées en fonction de la fréquence d’exploration.
Analyse 404 : Screaming Frog – Log File ?
Screaming Frog vous permet d’analyser tous les liens présents et les éventuelles erreurs 404 entre les liens internes ou vers des ressources externes, mais se limite à cela.
Les fichiers journaux peuvent également être utilisés pour identifier des URL qui ne sont plus présentes sur le projet analysé, mais qui ont pu être indexées dans la base de données de Google dans des versions antérieures du site web (non couvertes par les migrations seo précédentes).
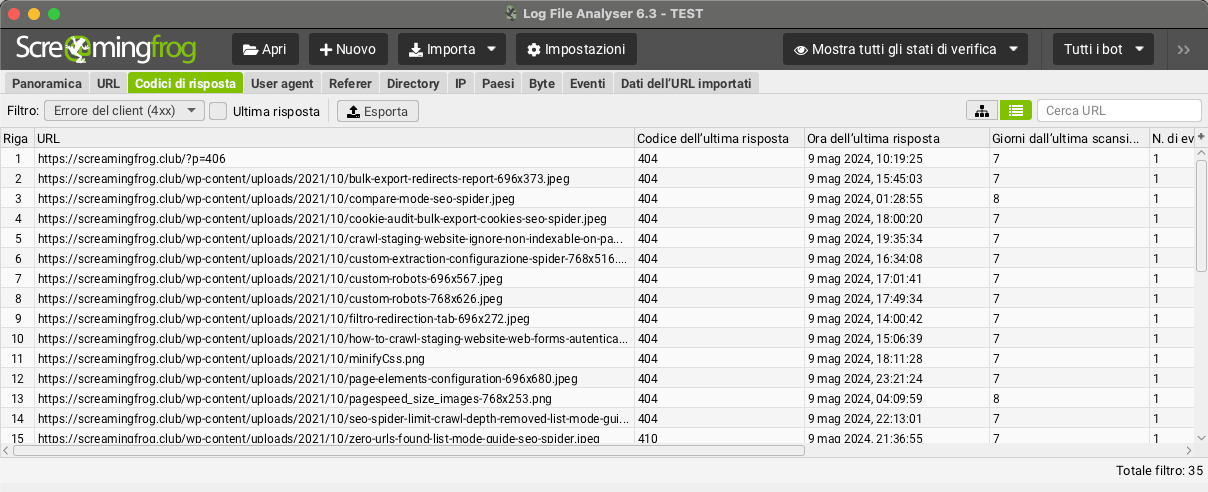
À ce stade de l’analyse, il est important de ne pas oublier de cocher la case « dernière réponse » à côté du filtre 4xx, sinon l’analyseur de fichiers journaux présentera toutes les URL qui ont un événement correspondant dans le temps (au lieu de la seule « dernière réponse » /« dernière réponse« ), ce qui donnera parfois un résultat non conforme puisque l’erreur peut avoir déjà été résolue depuis le premier jour où les fichiers journaux ont été enregistrés.
Réponses incohérentes
Un filtre très intéressant, qui fait écho au point précédent, est le filtre « incohérent », qui vous aide à identifier les ressources dont les réponses sont incohérentes dans les résultats, par exemple parce qu’un lien brisé a été corrigé ultérieurement ou parce que le site présente davantage d’erreurs de serveur interne dans des conditions de charge et qu’il s’agit d’un problème intermittent qu’il convient d’examiner.

Redirection de l’audit
Grâce aux enregistrements du journal, il sera possible de voir toutes les URL que les moteurs de recherche demandent et qui reçoivent une redirection en réponse.
Il s’agit non seulement des redirections sur le site, mais aussi des redirections historiques, qui sont encore demandées de temps à autre, peut-être en raison de migrations antérieures.
Pour afficher les URL avec le code de statut 3xx, il suffit d’utiliser l’onglet correspondant avec le filtre « Redirection (3XX) », ainsi que la case « Dernière réponse ».
Bot Spoofed
L’onglet IP et le filtre « état de vérification » défini sur « spoofed » permettent d’afficher rapidement les adresses IP des requêtes qui imitent les robots des moteurs de recherche, en utilisant leur chaîne user-agent, mais sans les vérifier. Grâce à ces données, il sera possible de bloquer les balayages et de soulager ainsi la charge de travail du serveur.

Si vous modifiez le filtre « statut de vérification » en « vérifié », vous pouvez afficher toutes les adresses IP des robots de moteur de recherche vérifiés. Cela peut s’avérer utile lors de l’analyse de sites web dont les pages sont adaptées à la localisation et dont le contenu varie en fonction du pays.
Identifier les grandes pages
Un autre élément très important lors de l’analyse des fichiers journaux est la différence de temps de réponse des ressources individuelles aux requêtes des robots.
Les pages très lourdes et peu performantes ont un impact considérable sur le budget d’exploration, de sorte qu’en analysant les « octets moyens » des URL, il sera facile et rapide d’identifier les domaines qui doivent être optimisés.
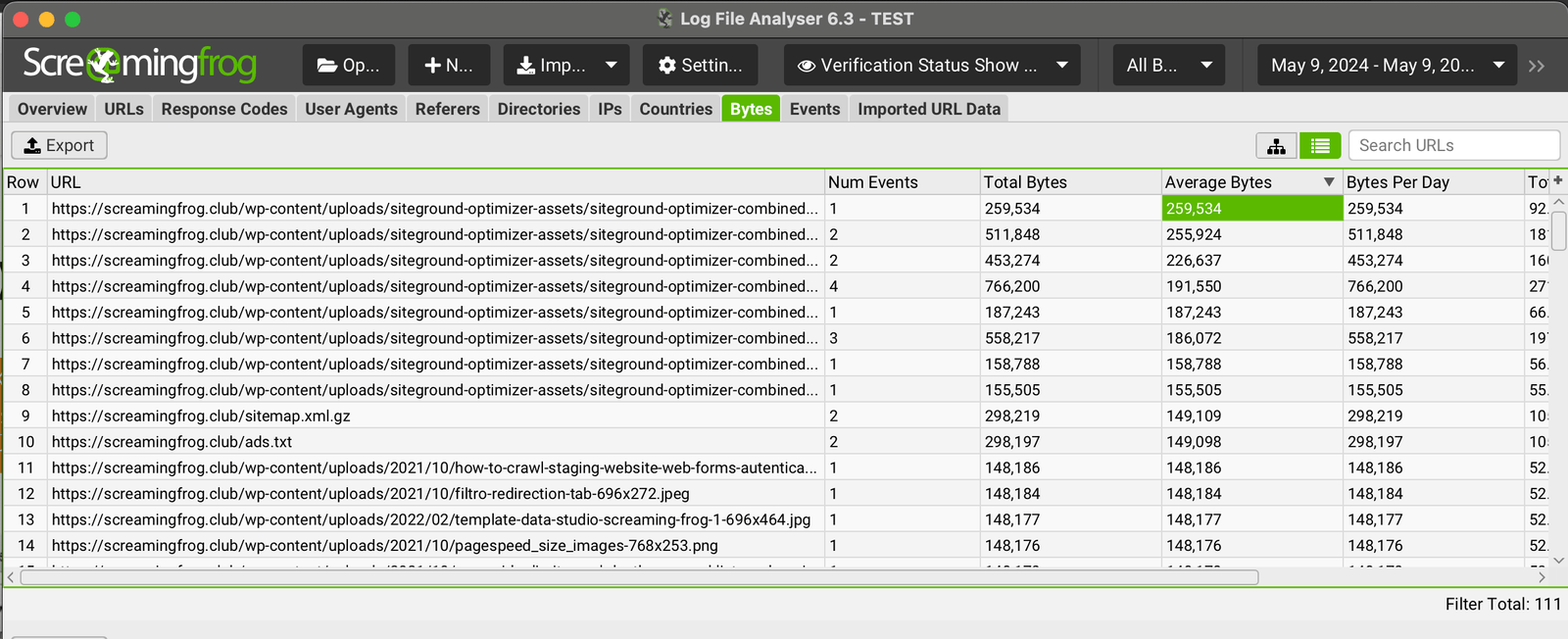
Analyse des fichiers crawl et de log file
L’une des analyses les plus intéressantes des fichiers journaux consiste à les comparer avec les données obtenues par crawl. Cette comparaison vous permettra de savoir si certaines URL ou des zones entières de votre site ne sont pas scannées par le spider.
Il suffit de télécharger les URLs obtenues avec un scan de Screaming Frog au format « .csv » et de les importer dans l’analyseur de fichiers log. En utilisant le filtre« Not in Log File » dans l’onglet URL, vous pouvez facilement trouver les zones sur lesquelles vous pouvez intervenir pour améliorer la navigabilité par le BOT, comme le Internal Linking.
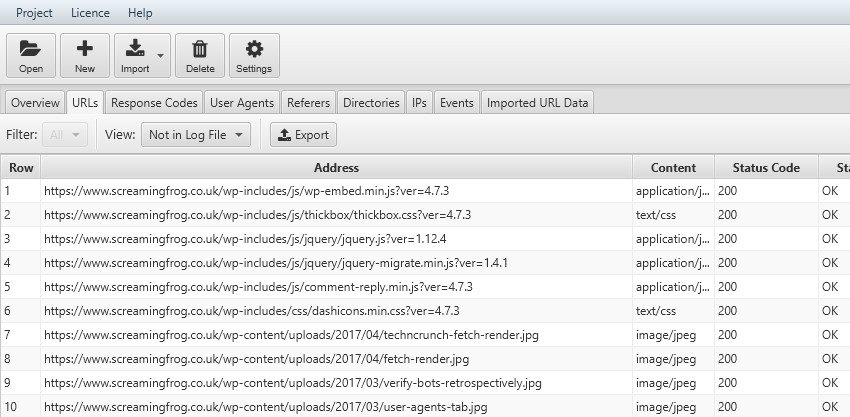
En inversant l’analyse« Pas dans les données URL« , il y aura des URL présentes dans les navigations du robot mais pas dans l’analyse de Screaming Frog ; dans ce scénario, vous trouverez toutes les occurrences d’adresses qui ne sont plus présentes ou de pages orphelines qui ne sont pas liées, mais qui sont présentes dans le site analysé. Ce dernier point peut également être analysé avec les API Ga4 et Search Console, qui permettent de trouver des ressources qui reçoivent des impressions ou des visites sans être liées en interne (par exemple, des pages avec des liens provenant de sites externes).
Piratage et fichiers journaux
Les fichiers journaux deviennent essentiels en cas de piratage ou de logiciels malveillants sur le site. Il arrive souvent que l’on se rende compte trop tard qu’un projet en ligne a été compromis, peut-être par des avertissements de la console de recherche ou par une chute drastique dans le Serp due à des pénalisations manuelles.
Dans ce cas, l’analyse et la suppression des URL compromises (« 410 ») peuvent ne pas être suffisantes (solution instantanée). Les fichiers journaux vous permettront de constater les dommages réels causés par la cyberattaque au moteur de recherche et d’obtenir une vue d’ensemble des pages ou des dossiers créés qui continueraient à causer des dommages s’ils n’étaient pas complètement supprimés.
Un cas très fréquent pourrait être un fichier de code ‘.php’ ou autre qui génère par intermittence de nouvelles ressources spammy ; dans ce cas, le balayage seul serait insuffisant, alors que grâce aux fichiers journaux, vous auriez plusieurs alertes au fil du temps avec le temps correspondant pour les trier.
Pages les plus consultées
Après cette étude approfondie, vous aurez certainement compris l’importance des fichiers journaux, mais j’aimerais également attirer votre attention sur un autre aspect que la simple recherche d’erreurs.
La connaissance des logs vous donne une vision à 360° de la stratégie et de l’architecture du site web. En fait, vous pourriez comparer les pages les plus consultées par les moteurs de recherche (en fonction des événements) et les pages les plus visitées. En cas d’incohérence, vous pourrez immédiatement modifier les liens internes ou restructurer votre architecture ou la « profondeur de crawl » des ressources individuelles, puis envoyer un nouveau plan du site en attendant la réponse du robot.
