




What are Log Files?
Web servers also produce other log files, such as error logs, but for purely SEO analysis we only need logs of access to a website.
Why analyze Log Files?
Log files are an incredibly powerful, but still underutilized, way to gain valuable information about how each Search Engine crawls your site.
This is why every Seo should analyze them even though access logs might be difficult to obtain from the client (and/or the hosting provider, server, and development team).
Analysis of log files can help you obtain the following results:
- Verify exactly what can and cannot be scanned. A crawl is a simulation, whereas log files show exactly what was scanned (full story).
- Visualize the responses encountered by search engines as they crawl (and compare the data in different scans over time). With Log Files analysis, problems can be qualitatively defined. If you find several 404s on your site during a crawl, it is difficult to tell which ones are the most important; by analyzing the log files, you can see how often they occurred, helping you prioritize their resolution.
- Identify crawling deficiencies, which could have broader implications at the site level (such as hierarchy or internal link structure).
- See which pages the search engines prioritize and consider the most important and which could be optimized to achieve a more consonant crawl rate. This condition is underestimated, but it is often the case that the strategic vision of the website does not match the responses of the Search Engine.
- Discover areas of wasted Crawl Budget (Crawl Budget).
- See Orphan URLs. If a URL is not internally linked, it will not be found by scanning the site. URLs linked only externally (or historically) will be reported in the logs allowing them to be managed, optimized or deleted.
- View changes over time. A crawl is a snapshot of the moment, while log files provide historical information about each resource.
By analyzing this invaluable data you will be able to preserve the Crawling Budget and define what elements are negatively impacting BOT navigation.
We see below some very common critical issues:
- Faceted browsing and session identifiers.
- Duplicate content on the site.
- Soft error pages.
- Hacked pages.
- Infinite spaces and proxies.
- Low quality content and spam.
Therefore, it is useful to avoid having the BOT waste time and energy in scanning such URLs, as it reduces activity and causes delays in scanning the most important pages.
Log File Analyser
The basis of log file analysis is to be able to verify exactly which URLs have been scanned by search engine bots. Through“Log File Analyser” you can import your log files by simply dragging and dropping the file of directly into the interface and automatically check Search Engine bots.
After importing you can use the “Verification Status” filter to display only verified ones and the “User-Agent” filter to get “all bots” or isolate a particular bot such as “Googlebot” or “Googlebot for smartphones” for granular analysis.
After this very simple and intuitive setup you will get exactly the URLs that have been scanned by the Bot filtered in the “URLs” tab classifying them by the number of events generated in a given time period.
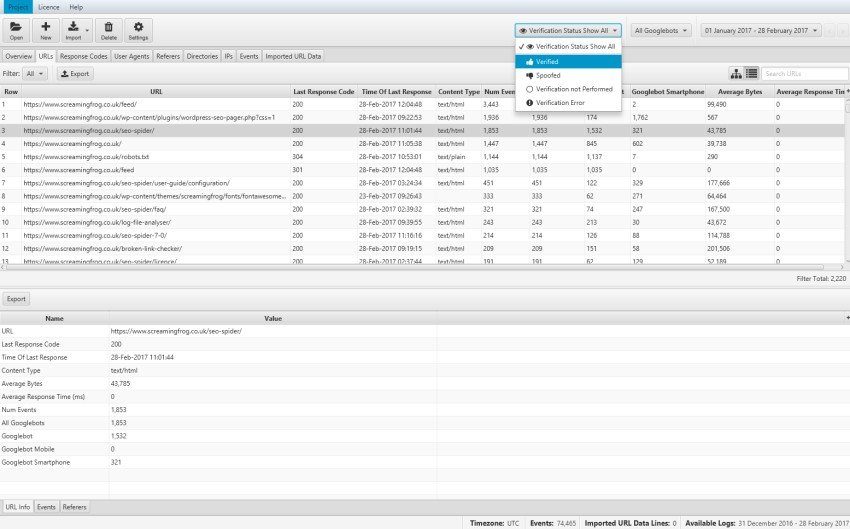
Identify low URL Value
Content for Seo is one of the most important ranking elements, and understanding which URLs are crawled and their frequency can help you uncover potential areas of wasted “Crawling Budget” that perhaps have “facetted navigation,” session IDs or duplicate content.
For example, through the tool’s search bar you might look for the presence of a question mark (?) in the “Path URL” (frequently found in e-commerce with filters), which will help you identify URLs with parameters that are perhaps not “canonicalized” and frequently browsed by the Google Bot.

As you can see in the example above the first entry generated 57 events corresponding to WordPress comments, so not exactly a high-value resource. In this specific case, it will be sufficient to disable comments to resolve this scenario and safeguard the Crawl Budget.
Clicking on the “URL” column header will allow you to sort them alphabetically and discover URLs that differ only by session id or parameters that should not be available to the BOT scan.
Clicking on “Num Events” will give you the resources that have, over a time interval, a higher and lower scanning frequency.
Scan Frequency Analysis
The frequency with which Googlebot requests a page is based on a number of factors such as the freshness of the content or the “Ranking” attributed by Google to one resource in relation to others. Although this concept is trivialized, it is very useful to analyze the number of events per URL as an indicator to help you identify any underlying problems among resources.
Through the filters in the main bar menu you will also be able to choose which events are generated by the individual Spider considering also Bots such as Bing, Yandex or others that could affect the data and create “false positives” in strategic analysis or drastically burden the server load.

Leaving the default “All BOT” setting instead will give you an overview of events processed by URL and a division of Spiders by scrolling to the right in the Tab.

Scanning Frequency Subdirectory
The next step in analyzing log files is to consider subdirectories (Directory Tab).
In this way, it will be possible to understand any performing areas or areas to be optimized that perhaps have critical issues that do not allow the crawler to navigate in a linear fashion.
With a focus of the subfolders you will be able to discover any “Waste Area.”
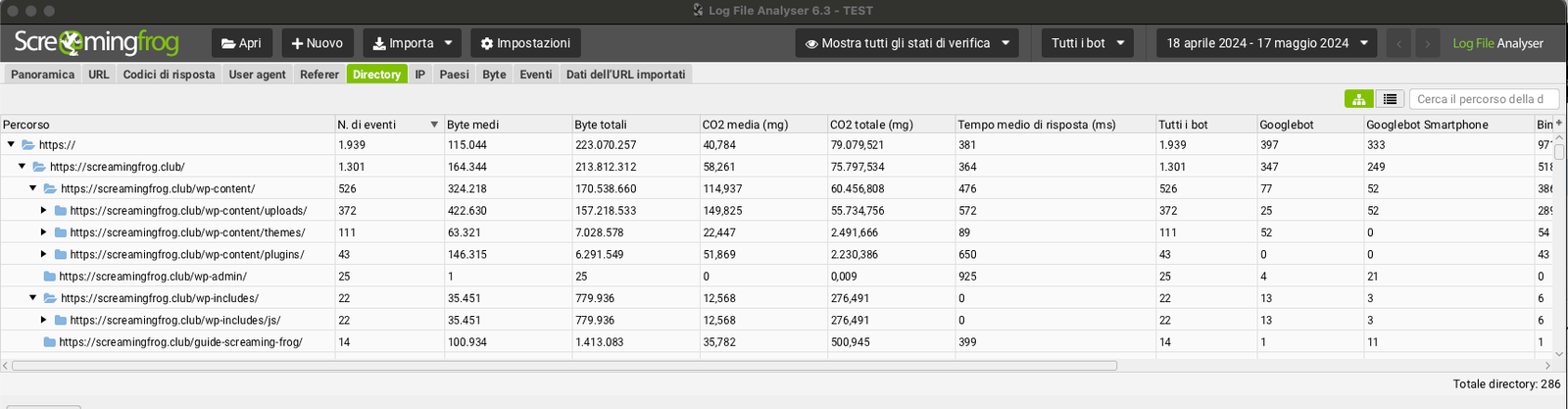
Scanning Frequency Content
While log files per se do not contain a content type, the Log File Analyser analyzes URLs for the most common formats and allows you to easily filter crawl frequency by content type, whether it is HTML, images, JavaScript, CSS, PDF, etc.
Through this analysis scenario you will be able to interpret how much time Google spends proportionally crawling each type of content.

Scan Frequency per User Agent
Another point of analysis is related to crawl frequencies based on different user-agents, which will be able to help you understand the respective performance of each individual Search Engine.
Based on this index, it will be possible to define the number of unique URLs crawled in the time period analyzed by providing a rough indication of the time it might take each search engine to crawl all URLs on the site. This will give you an overview of the “Crawl Budget” (Crawl Rate) that is devoted to your online project.
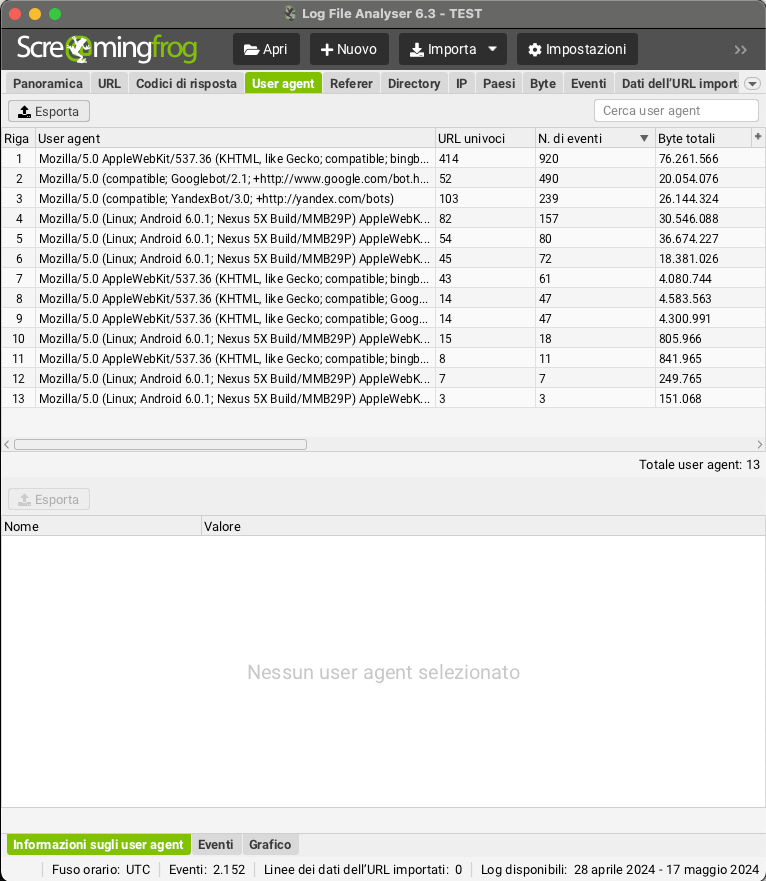
Very interesting to understand the behavior of various Bots but especially vital if the behavior of “Googlebot” and “Googlebot for smartphone” is diversified. For example, you will be able to understand whether there are bottlenecks in the mobile version or understand whether the site is considered “mobile first indexing.”
URL Crawl per day, week, and month
Through the “Overview” function you will have a timely summary of the overall events of the selected period with a very visual and intuitive dashboard.
Another point of view when analyzing log files is to consider the total number of unique URLs that were crawled, as well as the number of unique URLs crawled each day. In this case, it will then be possible to estimate how many days it might take the Search Engines to fully re-crawl all your URLs.

The dashboard allows you to export graph data in “.csv” format and, by hovering over the graph nodes see granularly the log results according to different user-agents or status codes..
404 Analysis and Server Errors
Logs allow you to quickly analyze the last response code that Search Engines encountered for each URL that was crawled.
In the “response codes” tab, you can use the filter to view 4XX client errors to discover broken links, or 5XX server errors.
You can also see which URLs are potentially the most important to fix, as they are sorted by crawling frequency.
404 Analysis: Screaming Frog or Log File?
Screaming Frog allows you to analyze all links present and any 404 errors between internal links or to external resources but is limited to that.
With log files, one can also identify URLs that are no longer present on the project under analysis but perhaps had been indexed in Google’s database in earlier versions of the website (not covered by previous seo migrations).
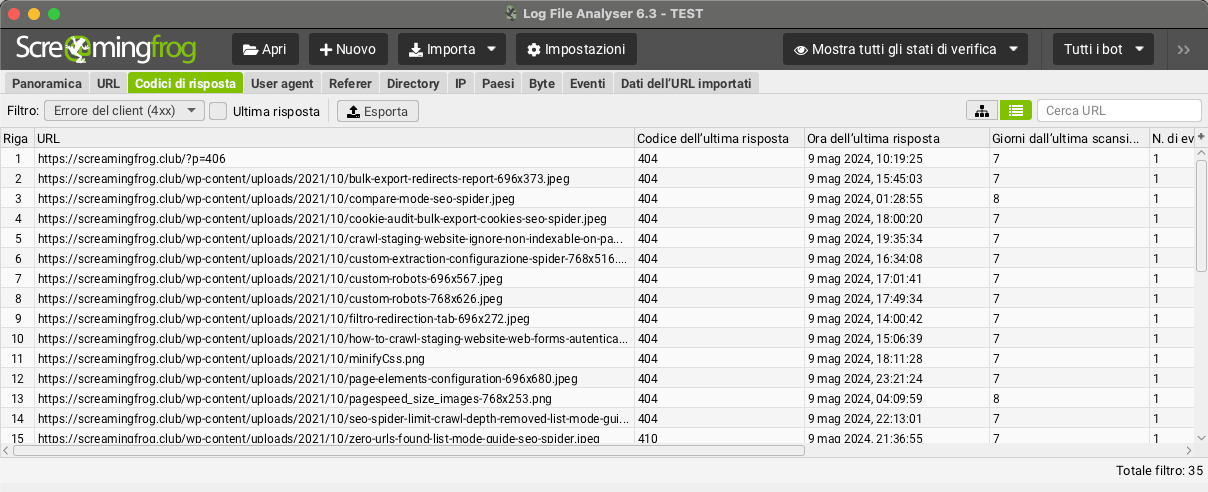
At this stage of analysis, it is important to remember to check the “Last Response” box next to the 4xx filter, otherwise the “Log File Analyser” will present all URLs that have a corresponding event over time (rather than just the “Last Response”/“Last Response“) sometimes giving a nonconforming result since the error may have already been resolved since the first day you started logging files.
Inconsistent Responses
A very interesting filter that echoes what was mentioned in the previous point is “incosistent,” which helps you identify which resources have inconsistent responses among the results; for example, because a broken link was later corrected, or because the site has more internal server errors under load conditions and there is an intermittent problem that needs to be investigated.

Audit Redirect
Through the log records, it will be possible to view all URLs that search engines request and receive a redirect as a response.
This not only includes redirects that are present on the site, but also historical redirects that are still requested from time to time, perhaps due to previous migrations.
To view Urls with status code 3xx it will be sufficient to use the related tab with the filter “Redirection (3XX),” along with the “Last Reply” box.
Bot Spoofed
The IP tab and the “verification status” filter set to “spoofed” allow you to quickly view the IP addresses of requests that emulate search engine bots, using their user-agent string, but without verifying them. Through this data, it will be possible to block scans and, as a result, lighten the work of the server.

If you change the “verification status” filter to “verified,” you can view all the IPs of the verified search engine bots. This can be useful when analyzing websites that have localization-friendly pages and serve different content based on country.
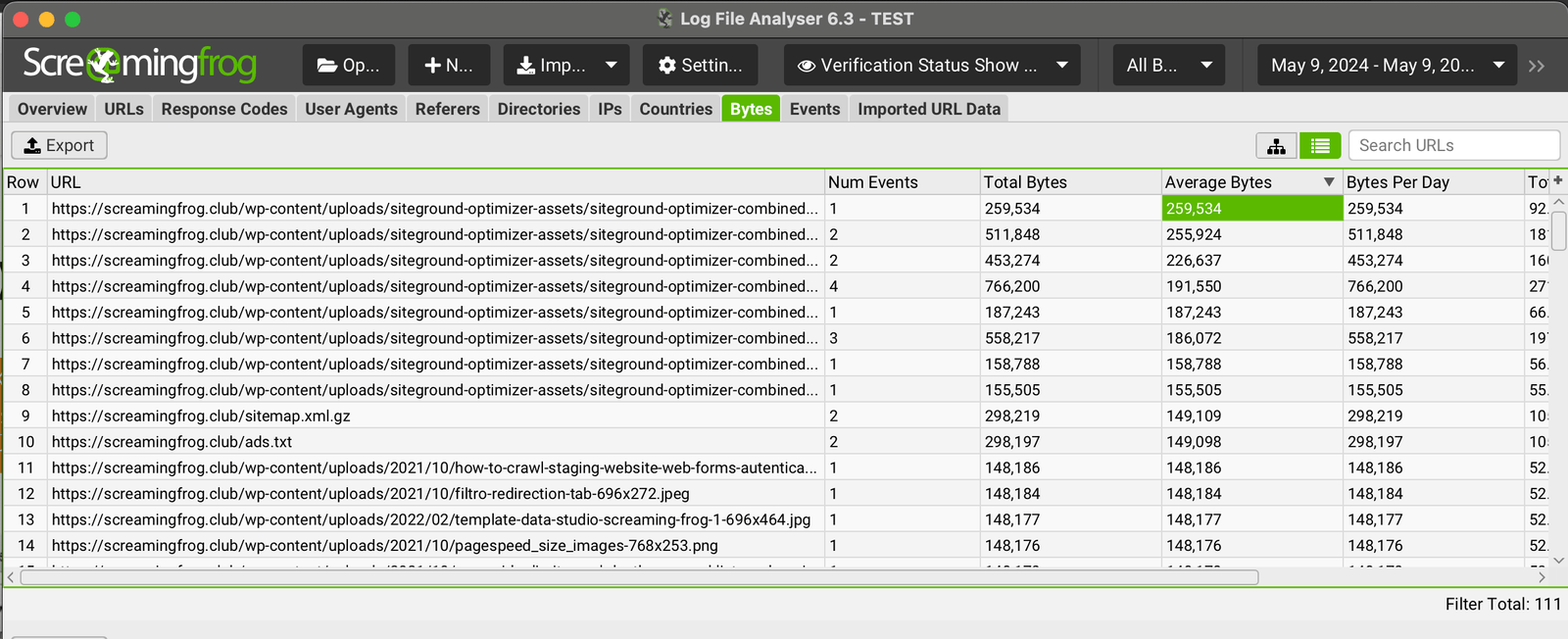
Identify Large Page Size
Another very important element during log file analyses are the different response times of individual resources to Bot requests.
Very heavy and underperforming pages greatly affect the crawling budget, so that by analyzing the “average bytes” of URLs, it will be quick and easy to identify areas that need to be optimized.
Crawl vs. Log File Analysis
One of the most interesting analyses of log files is to compare them with data obtained through a crawl. Through this comparison you will be able to understand whether certain URLs or entire areas of your site are not getting scans by the Spider.
It will be sufficient to download the URLs obtained with a Screaming Frog scan in “.csv” format and import them into Log File Analyser, through the“Not in Log File” filter of the URL tab you will be able to easily find the areas on which to intervene to improve navigability by the BOT, such as Internal Linking.
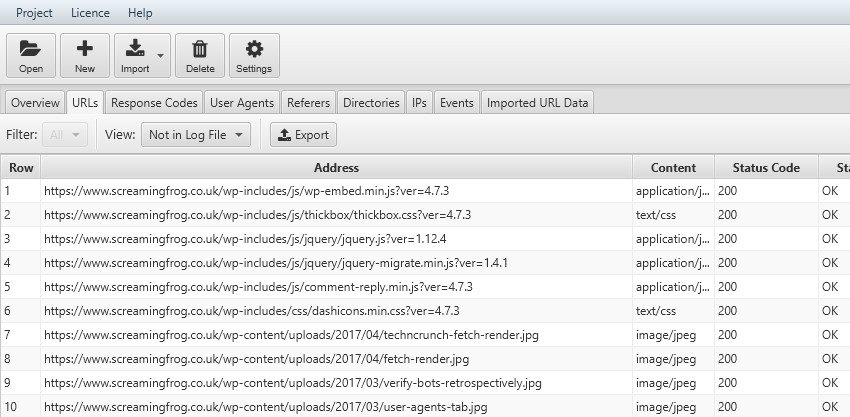
Reversing the“Not in URL DATA” analysis will have URLs that are present in Bot browsing but not in Screaming Frog scanning; in this scenario you will be able to find all occurrences generated by addresses that are no longer present or Orphan pages that are not linked, but are present in the site being analyzed. The latter point can also be analyzed with the Ga4 and Search Console APIs, which allow finding resources that receive Impressions or visits without being linked internally (e.g., pages with links from external sites).
Hacking and Log Files
Log Files become essential in case of hacking or malware on the site. Many times one realizes that an online project has been compromised too late perhaps through warnings from the search console or due to a drastic drop in Serp due to manual penalties.
In this case, scanning and removing the compromised (“410”- gone) URLs may not be enough (instant solution), and the Log files will allow you to see what the real damage of the cyber attack is to the Search Engine and get a full view of the pages or folders created that would continue to do damage if not deleted completely.
A very frequent case could be a “.php” code file or something else that intermittently generates new spammy resources; in this case scanning alone would be insufficient while through the log files you would have several alerts over time with relative time for fixes.
Top Crawled Pages
After this in-depth discussion you will surely have understood the importance of Log Files, but I would also like to draw your attention to another aspect other than merely searching for errors.
Knowledge of Logs gives you a 360-degree view of website strategies and architecture. In fact, you could compare the Top Pages for search engines (based on events) and what your most visited pages should be. If there are inconsistencies you will immediately be able to make Internal Linking changes or restructure your architecture or the “Crawl Depth” of individual resources and then submit a new sitemap while waiting for the Bot’s response.
