



Scansionare siti di grandi dimensioni
Come fare una scansione siti di grandi dimensioni con la modalità "Database Storage" e alcuni accorgimenti.

Modalità Database Storage
Per gestire la scansione di un sito da milioni di URL la modalità “Memory Storage” con archiviazione sulla RAM non è la scelta consigliata, per cui il primo passo che ti consiglio è lo switch a “Database Storage”.


Per ottenere il massimo delle performance dal Seo Spider con questa modalità dovresti prevedere una scheda di memoria SSD interna o esterna se il tuo sistema supporta la modalità UASP.
Memory Allocation
Scelta la modalità “Database Storage” il secondo passo è quello di incrementare la memoria allocata.
Di seguito un confronto di performance in base al numero massimo di URL che possono essere crawlerati.

Questi requisiti sono solo dei riferimenti, parti sempre dall’idea che maggiore è la memoria allocata migliori saranno le performance del Seo Spider.
Attributi da scansionare
Non sempre è necessario scansionare un intero sito quindi è buona norma adattare il crawl agli specifici focus dell’analisi in essere. Ricorda che più dati si raccolgono e più intensa sarà la richiesta di RAM.
Per scegliere quali metriche scansionare e quali non includere puoi modificare direttamente le impostazioni del Seo Spider.
Configurazione > Spider > Crawl
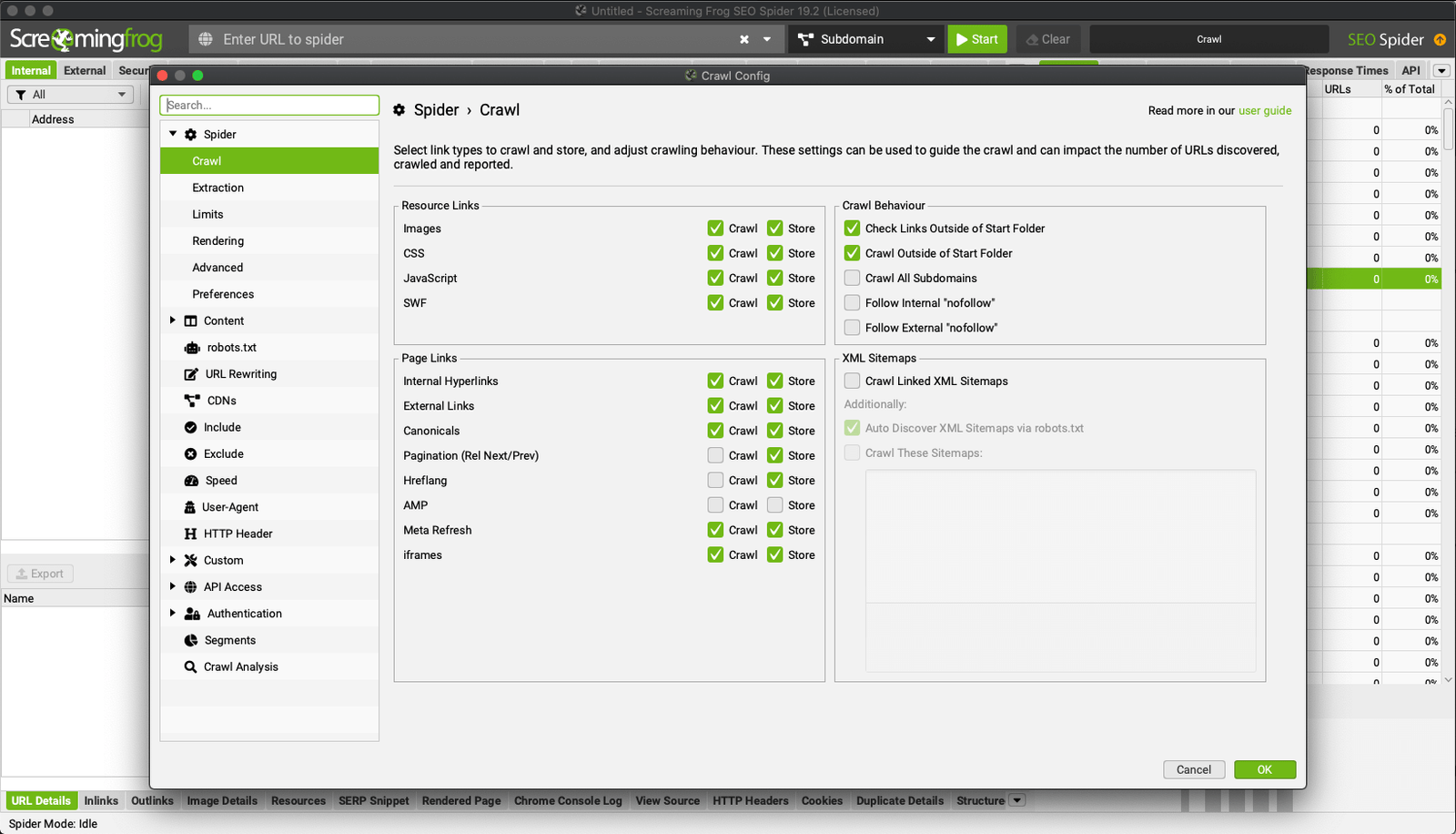
In base alla tipologia di analisi puoi scegliere se disabilitare la scansione e l’archiviazione dei seguenti elementi:
- Images*;
- CSS*;
- JavaScript*;
- SWF*.
*In termini di memoria ha molto senso disabilitare queste risorse ma nel caso utilizzi la modalità di rendering JavaScript dovrai abilitarle per non penalizzare il rendering.
- External Links;
- Canonicals;
- Pagination;
- Hreflang.
- AMP.
Altresì puoi disabilitare l’estrazione di alcuni elementi non essenziali come le “Meta Keyword” direttamente dalla schermata “Spider Configuration” o altri attributi che non siano strettamente necessari al momento dell’analisi scegliendo tra i “Page Details” (es. page title, word count, headings etc.), URL details, direttive o dati strutturati.

Oltre agli elementi sopra citati ti consiglio di disabilitare la funzione relativa alla posizione dei link nell’Html.
Config > Custom > Link Position

Altra best practice è quella di evitare la scansione di funzioni avanzate come le seguenti che possono essere incluse in una seconda fase di analisi:
- Custom Search – Ricerca personalizzata.
- Custom Extraction – Estrazione personalizzata.
- Integrazione di Google Analytics.
- Integrazione di Google Search Console.
- Integrazione di PageSpeed Insights.
- Spelling & Grammar – Ortografia e grammatica.
- Integrazione di Link Metrics (Majestic, Ahrefs e Moz).
Esclusione Urls
Per rendere la scansione maggiormente snella e meno impattante in termini di memoria puoi limitare la scansione ad aree specifiche del sito web ed escludere elementi come gli ordinamenti generati dalle “faceted navigation”, particolari parametri presenti sugli URL o URL infiniti con directory ripetute utilizzando la funzione “exclude”.
Questa funzione attraverso espressioni RegEX ti permette di escludere gli URL che non desideri scansionare. Fai però attenzione che se gli URL esclusi contengono dei collegamenti ad altre pagine anche queste ultime non saranno crawlerate.
Per comprendere al meglio l’importanza della funzione “Exclude” prendiamo in esame uno scenario reale, come il sito web John Lewis.

Utilizzando le impostazioni di default del Seo Spider, a causa dei numerosi ordinamenti, la scansione comprenderebbe una serie infinita di URL come da esempio qui sotto:
https://www.johnlewis.com/browse/men/mens-trousers/adidas/allsaints/gant-rugger/hymn/kin-by-john-lewis/selected-femme/homme/size=36r/_/N-ebiZ1z13ruZ1z0s0la1 .
Questa condizione è molto comune negli e-commerce che utilizzano le “faceted navigation“ per le marche, per il colore, la vestibilità dei pantaloni e altro ancora creando infinite combinazioni e appesantendo inesorabilmente il crawling.
Nel caso specifico ti basterà eseguire una scansione campionaria del sito web per individuare questa tipologia di modello di URL parametrato ed escluderlo.
Sottocartelle e Sottodomini
Se il sito web è molto consistente, puoi considerare la scansione separata dei sottodomini o ancora più granulare di particolari sottocartelle.
Per impostazione predefinita, il SEO Spider scansiona solo il sottodominio inserito, e tutti gli altri sottodomini incontrati sono trattati come link esterni apparendo nella finestra inferiore della scheda ‘Esternal’.
È possibile scegliere di scansionare tutti i sottodomini, ma ovviamente questo richiederà più memoria.
Il Seo Spider può anche essere configurato per scansionare solamente una sottocartella inserendo l’URL della “Subfolder” con relativo percorso e disabilitando “check links outside of start folder – controlla i link fuori dalla cartella iniziale” e “crawl outside of start folder – scansiona fuori dalla cartella iniziale”.
Configurazione > Spider > Check links outside of start folder | Crawl outside of start folder
Ad esempio, ipotizziamo tu voglia scansionare solamente l’area blog del sito di Screaming Frog.
La prima attività è quella di identificare la sottocartella ed eseguire il crawler; che nel nostro caso sarà: https://www.screamingfrog.co.uk/blog/.

Nota Bene: per scansionare una sottocartella ricorda di aggiungere lo slash finale “/blog/” altrimenti il Seo Spider non la riconosce come tale. Lo stesso problema lo potresti avere se la versione con lo “/” viene reindirizzata verso la sua versione senza.
In questo secondo caso puoi usare la funzione “include” e utilizzare una regola RegEx per la scansione (ad esempio “.*blog.*”).
Funzione Include
Oltre all’esclusione di aree e/o alla disabilitazione di elementi da scansionare e archiviare puoi optare di sfruttare la funzione “Include” che ti permette di limitare gli URL da scansionare tramite le espressioni RegEx.
Per esempio, se vuoi scansionare solo le pagine che presentano “search” nella stringa dell’URL ti basta semplicemente includere la RegEx “.*search.*” nella funzione “include”.

Prendendo in esame il sito di Screaming Frog otterresti i seguenti risultati

Campionamenti
Un altro modo per risparmiare tempo e rendere la scansione meno impattante in termini di memoria è quella di lavorare su dei campionamenti del sito web attraverso:
Limit Crawl Total – Limita la scansione totale : identifica la soglia massima di pagine da scansionare complessivamente.
Limit Crawl Depth – Limita la profondità della scansione: limita la profondità di scansione alle pagine più prossime in termini di click alla pagina di partenza (o la home) per ottenere un campione di tutti i modelli.
Limit Max URI Length To Crawl – Lunghezza massima URL da scansionare: limita la scansione di URL fino ad un numero massimo di caratteri nella stringa evitando gli URL molto profondi.
Limit Max Folder Depth – Limita la profondità massima delle cartelle: limita la scansione in base alla profondità delle cartelle.
Limit Number of Query Strings – Limita il numero di stringhe di query: limita la scansione di parametri in base al numero di query string. Se imposti il limite delle stringhe di query a ‘1’, permetti al Seo Spider di scansionare URL che presentano al massimo un singolo parametro (?=colore per esempio) nella stringa evitando combinazioni infinite.
Crawl siti di grandi dimensioni

RAFFAELE VISINTIN
Consulente Seo e autore delle guide di Screaming Frog Club.
