




Modo de almacenamiento de la base de datos
Para gestionar el escaneado de un sitio a partir de millones de URL, el modo «Almacenamiento en memoria» con almacenamiento en RAM no es la opción recomendada, por lo que el primer paso que recomiendo es cambiar a «Almacenamiento en base de datos».


Para obtener el máximo rendimiento de Seo Spider en este modo, debes proporcionar una tarjeta de memoria SSD interna o externa si tu sistema admite el modo UASP.
Asignación de memoria
Una vez elegido el modo «Almacenamiento de base de datos», el segundo paso es aumentar la memoria asignada.
A continuación se muestra una comparación del rendimiento basada en el número máximo de URL que se pueden rastrear.

Estos requisitos son sólo referencias, parte siempre de la idea de que cuanta más memoria se asigne, mejor será el rendimiento del Seo Spider.
Atributos a escanear
No siempre es necesario rastrear un sitio entero, por lo que es una buena idea adaptar el rastreo al enfoque específico del análisis en cuestión. Recuerda que cuantos más datos recopiles, más RAM necesitarás.
Para elegir qué métricas escanear y cuáles no, puedes editar directamente la configuración de la Araña Seo.
> > Configuración Spider Crawl
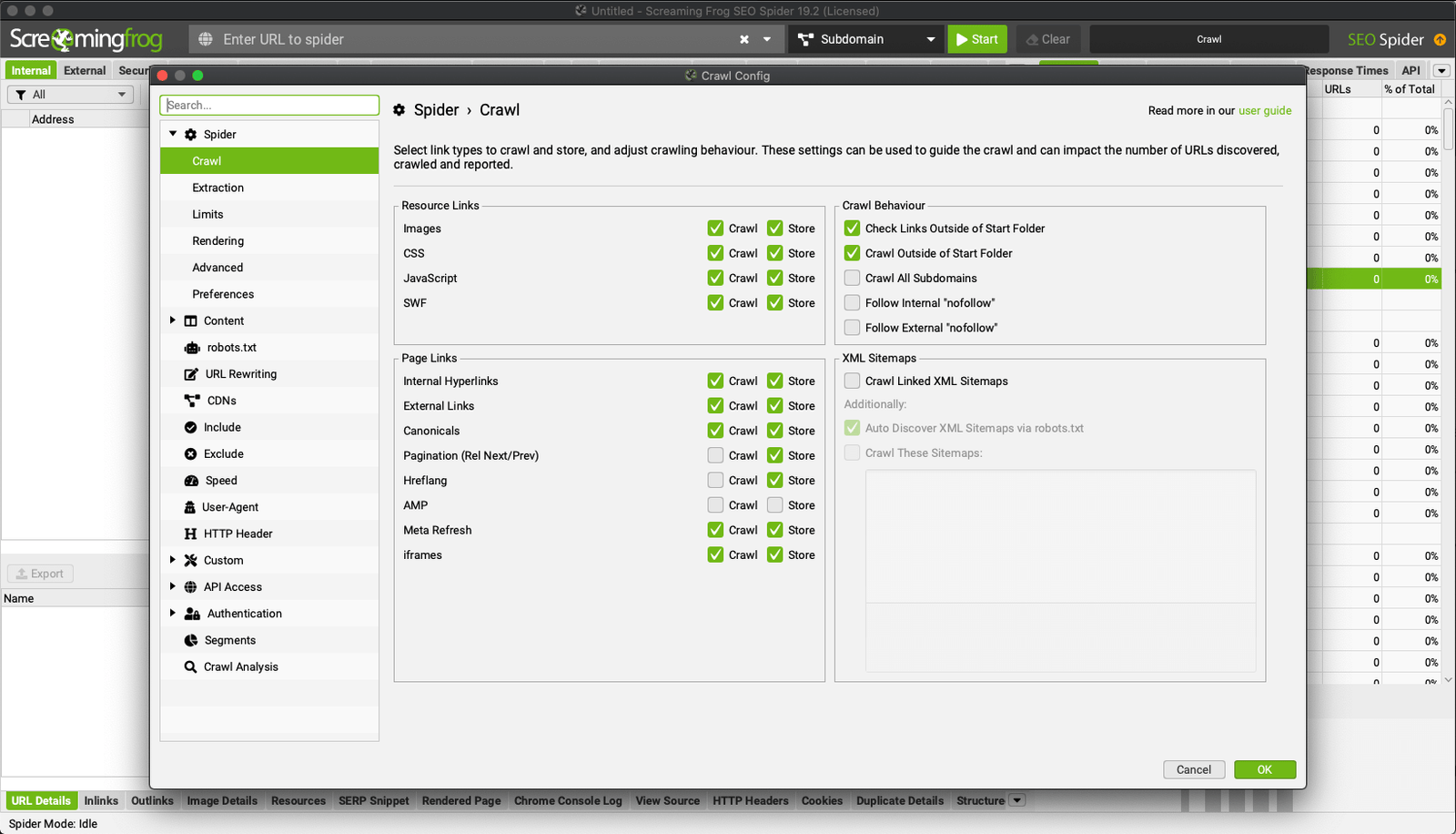
Según el tipo de análisis, puedes optar por desactivar el escaneado y archivado de los siguientes elementos:
- Imágenes*;
- CSS*;
- JavaScript*;
- SWF*.
*En términos de memoria, tiene mucho sentido desactivar estos recursos, pero si utilizas el modo de renderizado JavaScript, tendrás que activarlos para no penalizar el renderizado.
- Enlaces externos;
- Canónicos;
- Paginación;
- Hreflang.
- AMP.
También puedes desactivar la extracción de determinados elementos no esenciales, como las «Metapalabras clave», directamente desde la pantalla «Configuración de la araña», u otros atributos que no sean estrictamente necesarios en el momento del análisis, eligiendo entre «Detalles de la página» (por ejemplo, título de la página, recuento de palabras, encabezados, etc.), detalles de la URL, directivas o datos estructurados.

Además de los elementos anteriores, recomiendo desactivar la función de posición del enlace en Html.
> > Configurar la posición del enlace personalizado

Otra buena práctica es evitar escanear funciones avanzadas como las siguientes, que pueden incluirse en una segunda fase de análisis:
- Búsqueda personalizada – Búsqueda personalizada.
- Extracción personalizada.
- Integración de Google Analytics.
- Integración de Google Search Console.
- Integración de PageSpeed Insights.
- Ortografía y gramática – Ortografía y gramática.
- Integración de métricas de enlaces (Majestic, Ahrefs y Moz).
Urls de exclusión
Para que el rastreo sea más ágil y consuma menos memoria, puedes limitar el rastreo a áreas específicas del sitio web y excluir elementos como la ordenación generada por la «navegación facetada», parámetros concretos en las URL o URL infinitas con directorios repetidos utilizando la función «excluir».
Esta función mediante expresiones RegEX te permite excluir las URL que no desees escanear. Sin embargo, ten en cuenta que si las URL excluidas contienen enlaces a otras páginas, éstas tampoco serán rastreadas.
Para comprender mejor la importancia de la función «Excluir», examinemos un escenario real, como el sitio web de John Lewis.

Utilizando la configuración por defecto de la Araña Seo, debido a las numerosas clasificaciones, el rastreo incluiría una serie interminable de URLs, como en el ejemplo siguiente:
https://www.johnlewis.com/browse/men/mens-trousers/adidas/allsaints/gant-rugger/hymn/kin-by-john-lewis/selected-femme/homme/size=36r/_/N-ebiZ1z13ruZ1z0s0la1.
Esta condición es muy común en el comercio electrónico, que utiliza la «navegación facetada» para marcas, color, corte de pantalón y demás, creando infinitas combinaciones y sobrecargando inexorablemente el rastreo.
En este caso concreto, basta con realizar un escaneo de muestra del sitio web para detectar este tipo de patrón de URL parametrizado y excluirlo.
Subcarpetas y subdominios
Si tu sitio web es muy grande, puedes plantearte escanear subdominios por separado o incluso escanear subcarpetas concretas de forma más granular.
Por defecto, el SEO Spider sólo escanea el subdominio introducido, y todos los demás subdominios encontrados se tratan como enlaces externos, apareciendo en la ventana inferior de la pestaña «Externos».
Puedes elegir escanear todos los subdominios, pero obviamente esto requerirá más memoria.
El Seo Spider también puede configurarse para escanear sólo una subcarpeta introduciendo la URL de la «Subcarpeta» con su ruta y desactivando «comprobar enlaces fuera de la carpeta de inicio» y «rastrear fuera de la carpeta de inicio».
> > Configuración Araña Comprobar enlaces fuera de la carpeta de inicio | Rastrear fuera de la carpeta de inicio
Por ejemplo, supongamos que sólo quieres explorar la zona de blogs del sitio de Screaming Frog.
La primera tarea es identificar la subcarpeta y ejecutar el rastreador; que en nuestro caso será: https://www.screamingfrog.co.uk/blog/.

Nota: para escanear una subcarpeta recuerda añadir la barra final ‘/blog/‘, de lo contrario Seo Spider no la reconocerá como tal. Puedes tener el mismo problema si la versión con la «/» se redirige a su versión sin ella.
En este último caso, puedes utilizar la función «incluir» y utilizar una regla RegEx para el escaneo (por ejemplo, ‘.*blog.*’).
La función incluye
Además de excluir zonas y/o inhabilitar elementos para que no sean escaneados ni archivados, puedes optar por utilizar la función «Incluir», que te permite limitar las URL que se van a escanear mediante expresiones RegEx.
Por ejemplo, si sólo quieres escanear páginas con «búsqueda» en la cadena URL, sólo tienes que incluir RegEx ‘.*búsqueda.*’ en la función «incluir».

En el sitio web de Screaming Frog obtendrías los siguientes resultados

Muestreo
Otra forma de ahorrar tiempo y hacer que el escaneo consuma menos memoria es trabajar en el muestreo del sitio web a través de él:
Limitar rastreo total – Limitar rastreo total: identifica el umbral máximo de páginas que se rastrearán en total.
Limitar profundidad de rastreo – Limitar profundidad de rastreo: limita la profundidad de rastreo a las páginas más cercanas en términos de clics a la página de inicio (o home) para obtener una muestra de todos los patrones.
Limitar longitud máxima de URI a rastrear: limita el rastreo de URLs a un número máximo de caracteres en la cadena, evitando URLs muy profundas.
Limitar profundidad máxima de carpeta: limita el escaneado en función de la profundidad de la carpeta.
Limitar número de cadenas de consulta – Limita el número de cadenas de consulta. Si estableces el límite de la cadena de consulta en «1», permitirás que la araña Seo analice las URL que tengan como máximo un único parámetro (?=color, por ejemplo) en la cadena y evitarás las combinaciones infinitas.
